
1107 字
6 分钟
K-接邻(K Nearest Neighbor KNN)
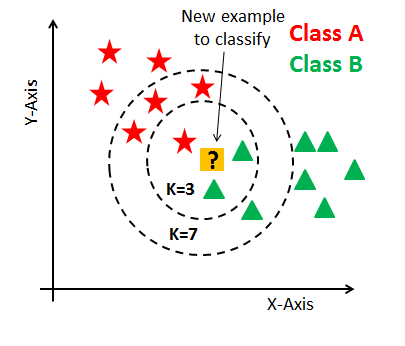
KNN算法的定义
如果一个样本在特征空间中的K个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别 通俗来说:通过你的“邻居”来判断你属于哪个类别
来源:KNN算法最早是由Cover和Hart提出的一种分类算法
算法的基本实现流程:
- 计算已知类别数据集中的点与当前点之间的距离
- 按距离递增次序排序
- 选取与当前点距离最小的k个点
- 统计前k个点所在的类别出现的频率
- 返回前k个点出现频率最高的类别作为当前点的预测分类
距离的计算
一般采用欧式距离来计算已知类别数据集中的点与当前点之间的距离 二维平面上点与间的欧式距离:
三维空间点与间的欧式距离:
维空间点与间的欧式距离(两个维向量):
K值选择
k值过小:容易受到异常点的影响 k值过大:容易受到样本均衡的问题 k值一般选择奇数而不是偶数
代码(鸢尾花分类)
计算距离
def get_euc_dist(ins1, ins2, dim): dist = 0 for i in range(dim): # 计算两个样本点之间在各个维度上的差值平方和 dist += pow((ins1[i] - ins2[i]), 2) return math.sqrt(dist) # 返回点与点之间的欧式距离选择k个距离最近的邻居
def get_neighbors(test_sample, train_set, train_set_y, k=3): distances = [] dim = len(test_sample) for i in range(len(train_set)): dist = get_euc_dist(test_sample, train_set[i], dim) distances.append((train_set_y[i], dist)) # 将每个样本的标签和对应的距离存入distances列表 distances.sort(key=operator.itemgetter(1)) # 按照距离进行排序(升序) neighbors = [] for i in range(k): neighbors.append(distances[i][0]) # 选择距离最近的k个样本中的类型标签 return neighbors # 返回k个邻居的所有类型标签在以上函数中,我们调用 get_euc_dist函数来计算距离,后根据距离选择k个距离最近的邻居。因为测试集中的测试点要与所有的训练集中的点进行距离计算,所以 get_euc_dist函数中参数2 ins2传入的是 train_set[i]列表
operator.itemgetter(n)是返回一个函数,该函数可以用于从可迭代对象(如元组、列表等)中提取第 n 个元素。然后,你可以将这个函数作为 sorted() 或 list.sort() 中的 key 参数进行排序。
因为此时 distances列表中同时存入了各个样本的标签和对应的距离,即:
distances = [(label_1, dist_1), (label_2, dist_2), (label_3, dist_3), ...]所以选择对其中下标为1的距离进行升序排序。
根据k个最近邻居的标签进行预分类
def predict_class_label(neighbors): class_votes = {} # 统计k个邻居中每个类别的出现次数 for i in range(len(neighbors)): neighbor_index = neighbors[i] if neighbor_index in class_votes: class_votes[neighbor_index] += 1 else: class_votes[neighbor_index] = 1 # 对类别进行排序,选取出现次数最多的类别作为预测结果 sorted_votes = sorted(class_votes.items(), key=operator.itemgetter(1), reverse=True) return sorted_votes[0][0]计算预测准确率的函数
def getAccuracy(test_labels,pre_labels): correct = 0 for x in range(len(test_labels)): if test_labels[x] == pre_labels[x]: correct += 1 return (correct/float(len(test_labels))) * 100.0主函数
if __name__ == '__main__':# 读取训练集数据,并定义列名 column_names = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species'] iris_data = pd.read_csv("iris_training.csv", header=0, names=column_names) iris = np.array(iris_data) # 分离出特征数据(前4列)和标签数据(最后1列) iris_train,iris_train_y = iris[:,0:4],iris[:,4]
# 读取测试集数据 iris_test = pd.read_csv("iris_test.csv", header=0, names=column_names) iris_test = np.array(iris_test) # 同样分离出特征数据和标签数据 iris_test,iris_test_y = iris_test[:,0:4],iris_test[:,4] print(iris_test_y) # 输出测试集的实际标签
pre_labels = [] # 输出测试集的实际标签 k = 3 for x in range(len(iris_test)): neighbors = get_neighbors(iris_test[x], iris_train, iris_train_y, k) result = predict_class_label(neighbors) pre_labels.append(result) print('> predicted=' + repr(result) + ', actual=' + repr(iris_test_y[x])) print('> predicted=' + repr(pre_labels)) accuracy = getAccuracy(iris_test_y, pre_labels) print('Accuracy: ' + repr(accuracy) + '%') K-接邻(K Nearest Neighbor KNN)
https://faina.me/posts/knn/