暑假集训第四篇周记(7月31日-8月6日)
摘要
涉及内容:贪心算法、二叉树、深搜(DFS)、宽搜(BFS)、堆
每日知识点
第一天 7月31日:贪心算法 (Greedy)
定义:将整个问题分解成多个步骤,每个步骤都选取当前步骤的最优方案,直到所有步骤结束,以达到整体最优;在每步都不考虑对后续步骤的影响;在后续步骤中也不再回头改变前面的选择,也就是不“悔棋”。
满足贪心法求解的问题需要满足以下特征:
- 最优子结构性质。当一个问题的最优解包含其子问题的最优解时,称此问题具有最优子结构性质,也称此问题满足最优性原理。也就是,从局部最优能扩展到全局最优。
- 贪心选择性质。问题的整体最优解可以通过一系列局部最优的选择得到。
第二天 8月1日:二叉树、深搜(DFS)、宽搜(BFS)、堆
树形数据结构是一种重要的非线性数据结构,它是由节点(或称为顶点)以及节点之间的关系(边或链接)组成的层次结构。树形结构通常用于模拟具有层级关系的数据,如组织结构、文件系统、XML文档等。
在树形结构中,有一个特殊的节点称为根节点,它没有父节点,是整个树的起始点。树的其他节点都有且只有一个父节点,除了根节点外,每个节点都可以有零个或多个子节点。节点之间的关系形成了树形结构,通常从根节点开始,逐层向下延伸。
以下是一些树形结构的常见术语/概念:
- 节点(Node):树中的基本单元,每个节点包含一个数据元素和若干指向子节点的指针。
- 根节点(Root):树的顶部节点,没有父节点。
- 叶子节点(Leaf):没有子节点的节点称为叶子节点,也称为终端节点。
- 父节点(Parent):有子节点的节点称为父节点。
- 子节点(Children):一个节点直接连接的下一层节点称为其子节点。
- 兄弟节点(Sibling):具有同一个父节点的节点称为兄弟节点。
- 子树(Subtree):一个节点及其所有后代节点构成的树称为子树。
- 深度(Depth):从根节点到某个节点的唯一路径的边数,根节点的深度为0。
- 高度(Height):从某个节点到其最远叶子节点的路径的边数,叶子节点的高度为0。
- 层次(Level):树中的每一层都包含着相同深度的节点。
二叉树:
是一种典型的树形数据结构,二叉树的每个节点最多有两个节点,分别称为左孩子和右孩子,以它们为根的子树称为左子树和右子树
二叉树有多种特殊形态,常见的形态包括:
- 满二叉树:在一棵二叉树中,所有非叶子节点都有两个子节点,且所有叶子节点都在同一层上。满二叉树的节点数等于 ,其中 h 为树的高度。
- 完全二叉树:在一棵二叉树中,除了最后一层外,其他层的节点数都达到最大,并且最后一层的节点都连续集中在最左边。完全二叉树可以看作是一棵满二叉树去掉最后几层的节点得到的树。
二叉树的遍历
宽度优先遍历:按照层次一层一层从上到下遍历二叉树。使用宽度优先搜索(BFS)
具体过程如下:
- 从根节点开始,将其加入队列(queue)。
- 重复以下步骤直到队列为空: a. 弹出队列的头部节点,将其标记为已访问。 b. 访问当前节点,并根据问题的需要进行相应的处理。 c. 将当前节点的所有未访问的邻居节点加入队列,继续下一轮循环
vector<int> e[N];//用来存x的邻点(x为任一节点)
int vis[N]; //标记x在队中
queue<int> q; //存入队的点的序列
void bfs(){
vis[1] = 1; //给即将入队的点打标记
q.push(1); //点入队
while(q.size()){
int x = q.front(); //标记x为根节点,是队伍的头
q.pop; //根节点出队
for(int y:e[x]){ //遍历存储了x邻节点的数组
if(vis[y]) continue; //如果某一节点打标,则说明已经入队过,跳过
vis[y]=1; //即将入队的点打标
q.push(y); //入队
}
}
}
深度优先遍历:
- 先序遍历:按照根节点,左子树,右子树的顺序遍历。遍历的第一个节点是根
void preorder(node *root){
cout << root -> value; //输出
preorder(root -> lson); //递归左子树
preorder(root -> rson); //递归右子树
}
- 中序遍历:按照左子树,根节点,右子树的顺序遍历。找到根节点,可以分辨哪些节点是左子树的,哪些节点是右子树的
void preorder(node *root){
preorder(root -> lson); //递归左子树
cout << root -> value; //输出
preorder(root -> rson); //递归右子树
}
- 后续遍历:按照左子树,右子树,根节点的顺序遍历。遍历的最后一个点是根
void preorder(node *root){
preorder(root -> lson); //递归左子树
preorder(root -> rson); //递归右子树
cout << root -> value; //输出
}
第三天8月2日:深度优先搜索(Depth-First-Search,DFS)
DFS的工作原理就是递归的过程,即“DFS = 递归”
从图的某个顶点(或树的根节点)开始,沿着一条路径遍历到底,直到无法继续或到达目标节点。然后回溯到前一个节点,继续遍历其他的路径,直到找到目标节点或遍历完所有可能的路径。
DFS使用递归或栈的数据结构来实现。当访问一个节点时,DFS将其标记为已访问,然后递归地访问它的所有未访问过的邻居节点。这样,DFS会先沿着一条路径尽可能深入,直到无法继续或到达终点,然后返回到上一个节点,继续遍历其他的路径。
DFS的主要特点是它是一种深度优先的搜索方式,即尽可能深地探索每个节点的子节点,而不是广度优先地探索它们。这使得DFS在找到解决方案或目标节点时可能更快,但也可能导致它陷入无限循环或进入非最优解。
DFS常用于解决以下问题:
- 图的连通性检测:判断图中的两个节点是否连通。
- 寻找图的路径:找到从一个节点到另一个节点的路径。
- 拓扑排序:对有向无环图进行排序,使得所有的边的起始节点都排在终止节点之前。
- 迷宫问题:在迷宫中寻找从起点到终点的路径。
第四天8月3日:广度优先搜索(Breadth-First-Search,BFS)
BFS的代码实现可描述为“BFS = 列队”。
它从图的某个顶点(或树的根节点)开始,逐层地向外扩展,先访问所有与起点距离为1的节点,然后是距离为2的节点,依次类推,直到无法继续或找到目标节点。
BFS使用队列的数据结构来实现。当访问一个节点时,BFS将其标记为已访问,并将其所有未访问过的邻居节点加入到队列中。然后从队列中取出下一个节点,重复上述步骤,直到队列为空,即所有可能的路径都被探索完毕。
队列内的节点存在以下特征:
- 处理万第层后,才会处理第层
- 队列中在任意时刻最多有两层节点,其中第层节点都在第层前面。
BFS的主要特点是它是一种广度优先的搜索方式,即先探索当前节点的所有邻居节点,再依次探索邻居节点的邻居节点,以此类推。这使得BFS在找到解决方案或目标节点时能够保证是最短路径,因为它先探索的是距离起点最近的节点。
BFS常用于解决以下问题:
- 最短路径问题:找到两个节点之间的最短路径。
- 图的连通性检测:判断图中的两个节点是否连通,并找到连通分量。
- 迷宫问题:在迷宫中寻找从起点到终点的最短路径。
- 拓扑排序:对有向无环图进行排序,使得所有的边的起始节点都排在终止节点之前。
以下是BFS的代码模板:
Q.push(初始状态); // 将初始状态入队,例如迷宫问题中的起点
while (!Q.empty()) {
State u = Q.front(); // 取出队首
Q.pop();//出队
for (枚举所有可扩展状态) // 找到u的所有可达状态v
if (是合法的) // v需要满足某些条件,如未访问过、未在队内等
Q.push(v); // 入队(同时可能需要维护某些必要信息)
}
提示
BFS是“全面扩散、逐层递进”;DFS是“一路到底、逐步回退”
部分题目详细分析与总结
第一天7月31日:贪心算法
第一题 部分背包问题
阿里巴巴走进了装满宝藏的藏宝洞。藏宝洞里面有 堆金币,第 堆金币的总重量和总价值分别是 。阿里巴巴有一个承重量为 的背包,但并不一定有办法将全部的金币都装进去。他想装走尽可能多价值的金币。所有金币都可以随意分割,分割完的金币重量价值比(也就是单位价格)不变。请问阿里巴巴最多可以拿走多少价值的金币?
Input
第一行两个整数 。
接下来 行,每行两个整数 。
Output
一个实数表示答案,输出两位小数
Sample
Input Output
4 50 240.00
10 60
20 100
30 120
15 45
代码
#include <iostream>
#include <algorithm>
using namespace std;
struct bag {
float w, v; //重量和价值
};
bool cmp(bag c, bag d) {
return (c.v / c.w) > (d.v / d.w); //自定义一个结构体排序的函数
}
int main() {
int N, T; //N堆金币,T的背包重量
cin >> N >> T;
bag b[105];
for (int i = 0; i < N; i++) {
cin >> b[i].w >> b[i].v;
}
sort(b, b + N, cmp);
float sum = 0.0;
float weight_s = 0.0;
for (int i = 0; i < N; i++) {
if (weight_s + b[i].w <= T) {
sum += b[i].v;
weight_s += b[i].w;
} else {
// 当前物品不能完整装入背包,只装入能够容纳的部分
float remaining_weight = T - weight_s;
sum += (b[i].v / b[i].w) * remaining_weight;
break;
}
}
printf("%.2f", sum);
return 0;
}
提示
所有物品的排序,是按照物品的单位价值从大到小排序的,这样的选择才是最优的。贪心算法中,需要每步选择最优的,以局部最优达到整体最优
第二天8月1日:二叉树、深搜、宽搜、堆
第一题:[NOIP2004 提高组] 合并果子 / [USACO06NOV] Fence Repair G
在一个果园里,多多已经将所有的果子打了下来,而且按果子的不同种类分成了不同的堆。多多决定把所有的果子合成一堆。
每一次合并,多多可以把两堆果子合并到一起,消耗的体力等于两堆果子的重量之和。可以看出,所有的果子经过 次合并之后, 就只剩下一堆了。多多在合并果子时总共消耗的体力等于每次合并所耗体力之和。
因为还要花大力气把这些果子搬回家,所以多多在合并果子时要尽可能地节省体力。假定每个果子重量都为 ,并且已知果子的种类 数和每种果子的数目,你的任务是设计出合并的次序方案,使多多耗费的体力最少,并输出这个最小的体力耗费值。
例如有 种果子,数目依次为 , , 。可以先将 、 堆合并,新堆数目为 ,耗费体力为 。接着,将新堆与原先的第三堆合并,又得到新的堆,数目为 ,耗费体力为 。所以多多总共耗费体力 。可以证明 为最小的体力耗费值。
Input
共两行。 第一行是一个整数 ,表示果子的种类数。
第二行包含 个整数,用空格分隔,第 个整数 是第 种果子的数目。
Output
一个整数,也就是最小的体力耗费值。输入数据保证这个值小于 。
Sample
Input Output
3 15
1 2 9
提示
对于 的数据,保证有 :
对于 的数据,保证有 ;
对于全部的数据,保证有 。
代码
#include <iostream>
#include <queue>
using namespace std;
int main() {
// 创建一个最小堆优先队列,用于存储果子堆的大小
priority_queue<int, vector<int>, greater<int>> pq;
int n;
cin >> n; // n 堆果子
while (n--) {
int x;
cin >> x;
pq.push(x); // 将每堆果子大小加入优先队列中
}
int energy = 0; // 表示当前合并的两堆果子的能量值
int sum = 0; // 表示合并所有果子的总能量值
// 当优先队列中还有多于一堆果子时,继续合并
while (pq.size() > 1) {
int a = pq.top(); // 取出当前最小的一堆果子
pq.pop();
int b = pq.top(); // 取出次小的一堆果子
pq.pop();
energy = a + b; // 合并两堆果子得到的能量值
pq.push(energy); // 将能量值加入优先队列,表示合并后的果子堆
sum += energy; // 累计总能量值
}
cout << sum << endl; // 输出最终合并所有果子的总能量值
return 0;
}
第二题:堆(模板)
给定一个数列,初始为空,请支持下面三种操作:
- 给定一个整数 ,请将 加入到数列中。
- 输出数列中最小的数。
- 删除数列中最小的数(如果有多个数最小,只删除 个)。
Input
第一行是一个整数,表示操作的次数 。接下来 行,每行表示一次操作。每行首先有一个整数 表示操作类型。
- 若 ,则后面有一个整数 ,表示要将 加入数列。
- 若 ,则表示要求输出数列中的最小数。
- 若 ,则表示删除数列中的最小数。如果有多个数最小,只删除 个。
Output 对于每个操作 ,输出一行一个整数表示答案。
Sample
Input Output
5 2
1 2 5
1 5
2
3
2
- 对于 的数据,保证 。
- 对于 的数据,保证 。
- 对于 的数据,保证 ,,。
#include <bits/stdc++.h>
using namespace std;
priority_queue<int, vector<int>, greater<int>> q;
int main() {
int n;
scanf("%d", &n); // 输入操作次数
while (n--) {
int op;
scanf("%d", &op); // 输入操作类型
if (op == 1) {
int x;
scanf("%d", &x); // 输入要插入的元素 x
q.push(x); // 将 x 加入优先队列中
} else if (op == 2) {
printf("%d\n", q.top()); // 输出当前优先队列中最小的元素
} else {
q.pop(); // 移除当前优先队列中最小的元素
}
}
return 0;
}
第三天8月2日:深度优先搜索(Depth-First-Search,DFS)
第一题 N皇后问题 (模板题、经典)
在的棋盘上放置N个皇后而彼此不受攻击(即在棋盘的任一行,任一列和任一对角线上不能放置2个皇后),编程求解所有的摆放方法。
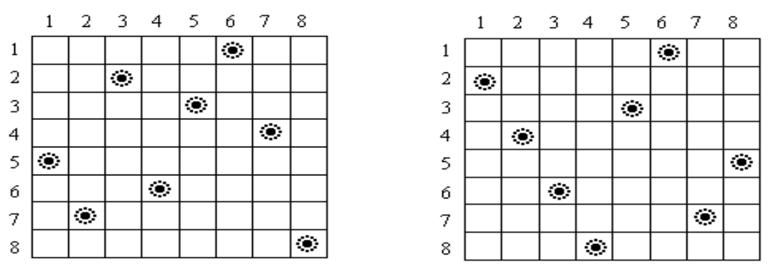
Input:
Output:每行输出一种方案,每种方案顺序输出皇后所在的列号,每个数占5列。若无方案,则输出no solute!
Sample:
Input: Output:
4 2 4 1 3
3 1 4 2
思路:
我们需要建立 a[i]数组,表示第i行的皇后放在第a[i]列,以及bool类型的 b[]、c[]、d[]数组分别标记当前列,当前两条对角线是否可用,若为false即为存在冲突,不能在棋盘上摆皇后,进行剪纸,后续行不用进行这一列的搜索。因为是一行一行摆皇后的,所以皇后在行之间的冲突不需要标记。
其中,关于对角线的冲突标记,可以发现同一左对角线的格子下标 i+j为定值,同一右对角线的格子下标 i-j为定值。
代码
#include <iostream>
#include <cstring>
#include <bits/stdc++.h>
using namespace std;
int n;
int mp[10][10] = {0}; // 初始化棋盘
int a[20]; // 第i行的皇后放在第ai列
bool b[20], c[40], d[40]; // 标记当前列,当前左对角线,当前右对角线是否可用
bool foundSolution = false; // 标记有没有找到答案
void ans() {
foundSolution = true;
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= n; j++) {
if (j == a[i]) printf("%5d",j);
else;
}
}
cout << endl; // 输出整个棋盘后再换行一次
}
void dfs(int i) {
for (int j = 1; j <= n; j++) {
if (b[j] && c[i + j] && d[i - j + n]) { //必须全为真,才能在棋盘上摆皇后
a[i] = j; // 第i行的皇后放在第j列
b[j] = false; //冲突标记
c[i + j] = false;
d[i - j + n] = false;
if (i < n) dfs(i + 1);
else ans();
b[j] = true;
c[i + j] = true;
d[i - j + n] = true; // 回溯,回溯到这一列皇后摆放之前的情况,进行下一次放皇后
}
}
}
int main() {
cin >> n; // 获取n个皇后
memset(b, true, sizeof(b));
memset(c, true, sizeof(c));
memset(d, true, sizeof(d));
dfs(1); // 开始摆放第一个皇后(第一行)
if (!foundSolution) {
cout << "no solute!" << endl;
}
return 0;
}
第二题 全排列问题
输出自然数1到n所有不重复的排列,即n的全排列,要求所产生的任一数字序列中不允许出现重复的数字。
Input :n(1≤n≤9)
Output:由1~n组成的所有不重复的数字序列,每行一个序列。每个数字占5列。
Input Output
4 1 2 3 4
1 2 4 3
1 3 2 4
1 3 4 2
1 4 2 3
1 4 3 2
2 1 3 4
2 1 4 3
2 3 1 4
2 3 4 1
2 4 1 3
2 4 3 1
3 1 2 4
3 1 4 2
3 2 1 4
3 2 4 1
3 4 1 2
3 4 2 1
4 1 2 3
4 1 3 2
4 2 1 3
4 2 3 1
4 3 1 2
4 3 2 1
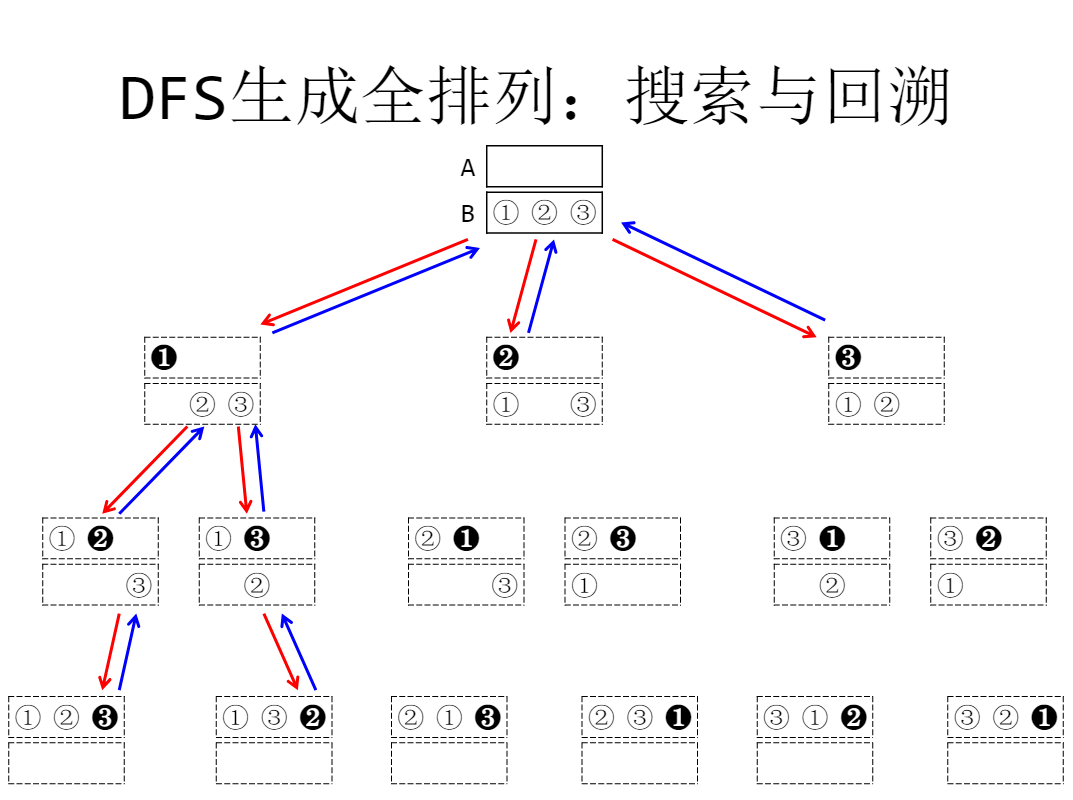
代码:
#include <stdio.h>
int a[10], b[10];
// 定义递归函数f,用于生成全排列
// n: 全排列的长度
// p: 当前排列的位置
void f(int n, int p) {
// 如果当前排列位置p大于n,则表示已经生成了一个全排列
if (p > n) {
// 输出当前生成的全排列
for (int i = 1; i <= n; i++) {
printf("%5d", a[i]);
}
printf("\n");
return;
}
// 循环遍历每个数字,尝试将其放到当前排列的位置p上
for (int i = 1; i <= n; i++) {
// 如果数字i还没有被使用(标记数组b中为1),则将其放到当前排列的位置p上
if (b[i] == 0) continue;
b[i] = 0; // 标记数字i已经被使用
a[p] = i; // 将数字i放到当前排列的位置p上
f(n, p + 1); // 递归调用f,生成下一个位置的排列
b[i] = i; // 恢复数字i的可用状态
a[p] = 0; // 清空当前排列的位置p上的数字
}
}
int main() {
int n;
scanf("%d", &n);
// 初始化标记数组b,表示数字1到n都可用
for (int i = 1; i <= n; i++) {
b[i] = i;
}
// 调用递归函数f,生成全排列
f(n, 1);
return 0;
}
第四天8月3日:广度优先搜索(Breadth-First-Search,BFS)
第一题 A - 马的遍历
有一个 的棋盘,在某个点 上有一个马,要求你计算出马到达棋盘上任意一个点最少要走几步。
Input:输入只有一行四个整数,分别为 。
Output:一个 的矩阵,代表马到达某个点最少要走几步(不能到达则输出 )。
Sample
Input Output
3 3 1 1 0 3 2
3 -1 1
2 1 4
对于全部的测试点,保证 ,。
代码
#include <bits/stdc++.h>
using namespace std;
int n, m; // n行, m列
int dir[][2] = {{-1, -2}, {-2, -1}, {-2, 1}, {-1, 2}, {1, 2}, {2, 1}, {2, -1}, {1, -2}}; // 搜索的方向向量
int mp[405][405]; // 存储每个位置到起点的最短距离
//位置的结构体
struct pos {
int r, c, d; // r行,c列,d表示距离
pos(int a = 0, int b = 0, int d = 0) : r(a), c(b), d(d) {}
};
queue<pos> q; // 定义队列,用于广度优先搜索
void bfs(int r, int c); // 定义广度优先搜索函数
int main() {
int sr, sc;
cin >> n >> m >> sr >> sc; // 输入地图的行数n,列数m,以及起点坐标sr和sc
memset(mp, -1, sizeof mp); // 初始化mp数组为-1
bfs(sr, sc); // 进行广度优先搜索,计算每个位置到起点的最短距离
// 输出每个位置到起点的最短距离
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
cout << mp[i][j] << '\t';
}
cout << endl;
}
return 0;
}
void bfs(int r, int c) {
q.push(pos(r, c, 0)); // 起点入队,并将其距离设为0
mp[r][c] = 0; // 将起点的最短距离设为0
while (!q.empty()) {
pos p = q.front(); // 取队首,并出队
q.pop();
for (int i = 0; i < 8; i++) {
int nr = p.r + dir[i][0]; // 新行
int nc = p.c + dir[i][1]; // 新列
int nd = p.d + 1; // 新的距离为原距离加1
if (nr >= 1 && nr <= n && nc >= 1 && nc <= m && mp[nr][nc] == -1) {
mp[nr][nc] = nd; // 更新新位置的最短距离
q.push(pos(nr, nc, nd)); // 将新位置入队
}
}
}
}
从给定起点出发,使用广度优先搜索算法计算每个位置到起点的最短距离,并将结果输出。其中,mp数组用于存储每个位置到起点的最短距离,初始值为-1表示尚未计算。bfs函数用于进行广度优先搜索,通过遍历8个方向的相邻位置,将最短距离不断更新,并将新位置加入队列,直到队列为空为止。最后输出每个位置到起点的最短距离。
第二题 Lake Counting S
由于近期的降雨,雨水汇集在农民约翰的田地不同的地方。我们用一个 的网格图表示。每个网格中有水(W) 或是旱地(.)。一个网格与其周围的八个网格相连,而一组相连的网格视为一个水坑。约翰想弄清楚他的田地已经形成了多少水坑。给出约翰田地的示意图,确定当中有多少水坑。
输入第 行:两个空格隔开的整数: 和 。
第 行到第 行:每行 个字符,每个字符是 W 或 .,它们表示网格图中的一排。字符之间没有空格。
输出一行,表示水坑的数量。
Due to recent rains, water has pooled in various places in Farmer John's field, which is represented by a rectangle of N x M (1 <= N <= 100; 1 <= M <= 100) squares. Each square contains either water ('W') or dry land ('.'). Farmer John would like to figure out how many ponds have formed in his field. A pond is a connected set of squares with water in them, where a square is considered adjacent to all eight of its neighbors. Given a diagram of Farmer John's field, determine how many ponds he has.
Input:
Line 1: Two space-separated integers: N and M * Lines 2..N+1: M characters per line representing one row of Farmer John's field. Each character is either 'W' or '.'. The characters do not have spaces between them.
Output:
Line 1: The number of ponds in Farmer John's field.
Sample:
10 12
W........WW.
.WWW.....WWW
....WW...WW.
.........WW.
.........W..
..W......W..
.W.W.....WW.
W.W.W.....W.
.W.W......W.
..W.......W.
3
提示
OUTPUT DETAILS: There are three ponds: one in the upper left, one in the lower left, and one along the right side.
代码
#include <iostream>
#include <queue>
using namespace std;
int n,m; // n行,m列
char mp[105][105];
//八个方向,左、左上、上、右上、右、右下、下、左下
int dir[][2]={{-1,0},{-1,1},{0,1},{1,1},{1,0},{1,-1},{0,-1},{-1,-1}};
struct pos{
int r,c; //r行,c列
};
void bfs(pos p);
int main() {
cin >> n >> m;
//获取地图信息
for(int i=1;i<=n;i++){
for(int j=1;j<=m;j++){
cin >> mp[i][j];
}
}
int cnt = 0;
for(int i=1;i<=n;i++){
for(int j=1;j<=m;j++){
if(mp[i][j] == 'W') {
bfs((pos){i,j});
cnt ++;
}
}
}
cout << cnt << endl;
return 0;
}
void bfs(pos p){
queue<pos> q;
//起点入队,并标记为干地
q.push(p);
mp[p.r][p.c] = '.';
while(!q.empty()){
//取队首,并出队
pos p1 = q.front();
q.pop();
for(int i = 0;i < 8;i++){
int nr = p1.r + dir[i][0]; //新行
int nc = p1.c + dir[i][1]; //新列
if(nr >= 1 && nr <= n && nc >=1 && nc <= m && mp[nr][nc]=='W'){
q.push((pos){nr,nc});
mp[nr][nc] = '.';
}
}
}
}